

In my most recent article, I used convex hulls to measure floor spacing for both teams at a certain point in time. Spacing is very important in basketball because when the defense is spread out, it is easier for the offense to penetrate and score inside which is a necessity for a successful offense.

In order to accomplish positive spacing, a team needs to have perimeter shooting threats that force the defense to spread themselves out. The 2016 Golden State Warriors were a great example of this phenomenon. The presence of all-time great shooters like Stephen Curry and Klay Thompson makes it easier for the rest of the team to operate.
Using basketball terminology, this is sometimes referred to as ‘gravity.’ Gravity is the tendency of NBA defenders to be pulled towards offensive players. Some players have more gravity than others. Defenders are always aware of the threat of Curry’s shooting, so they are naturally drawn to him on the perimeter. Meanwhile, defenses aren’t going to worry too much about Andre Roberson spotting up at the top of the key. The question I want to answer: can you quantify this defensive reaction using player tracking data?
While I’ll be focusing on gravity that increases the spacing of the defense, know that this isn’t the only type of gravity that exists. In his prime, Shaquille O’Neal drew defenders towards him every time he got the ball in the post. It would be more complicated to try to quantify both types of gravity at the same time, though, so we’ll simply focus on perimeter gravity.
First, I used game logs with player tracking data from this GitHub repository to create a data frame of 1482 offensive plays ran by the Golden State Warriors in their historic 2015-16 regular season campaign. This isn’t a large sample size, unfortunately, but the NBA no longer makes this data available so it’s all we’ve got. I could do this for all thirty teams, but this is basically just a fun experiment and doing it for every team would take far more time. And the sole team I chose to analyze was the Warriors because … well, they won 73 games, how could they not be the obvious choice?
Let’s take a look at a small portion of our data frame:

The ‘event_id’ is unique for every play within a single game, while the ‘moment’ is unique for every instant within a single play. We are looking at one moment for each play, which is the first moment that the ball is within 28 feet of the basket and all players on both teams are set (so not every play is included, which is the intention – we don’t want fast breaks). The variables ‘off_p#’ give the unique player ID for the Warriors’ players on the floor during a given play. The ‘off_space’ and ‘def_space’ variables are just the areas of the convex hulls created containing all five points representing the offensive and defensive players, while ‘diff’ is the difference between the two.
The offensive player variables contain 14 unique player IDs in total. In other words, in the course of these 1482 plays, 14 different players stepped onto the court to play for the Warriors.
Our goal is to use to create a new data frame with a column for each of those 14 players. One play will still represent one row. Each column represents a certain player. If that player is on the floor during the play, we put a 1 in the appropriate cell. Otherwise, we put a 0. Because a team has exactly five players on the floor, there will always be exactly five ones in a row.
Our new data frame will also have a column that serves as our dependent variable. In this case, I went with the convex hull area which represents the spacing of the defense so we can determine which players’ presence on the court is correlated with an increase in the defensive spacing. This is the ‘def_space’ variable in the original data frame.
Our new data frame looks like this:

Just so you know, the computer knows which unique player ID is being represented by each column, so at the end of this experiment we’ll be able to match our nameless results to, well, names. For now, let’s just take a look at the ‘p9’ column so we can understand this data frame. We can see that Player 9 was on the court for the first three plays, but not the subsequent two plays. As you can see from the ‘def_space’ column, the defense’s spacing decreased fairly significantly when he checked out of the game.
However, this isn’t the only factor that changes. In the last two plays, Player 1 also checked into the game after having not played the first three plays. So, did the defense become less spread out because of Player 1’s presence or the lack of Player 9’s presence? Or both?
This is the problem with just looking at basic on-off splits. We could easily just calculate the average defensive spacing for each player when they’re on the court and when they’re off the court and subtract the two to determine their impact, but this doesn’t account for the teammates they play with. Andrew Bogut got a lot of minutes with Curry and Thompson, so he would benefit from such a technique even though he definitely isn’t stretching out any defenses. That’s why we’re tracking every player on the floor for every play. The only problem with this technique is that it is noisy in smaller samples. Adjusted plus / minus metrics which account for different lineups are best used in multi-season samples. Unfortunately, our sample is less than half of a season, so it will be susceptible to some of this noise.
Anyway, the current data frame has 1482 rows, one for each play. Time to cut it down. The new objective is to have every row represent a unique lineup (or a unique combination of 0s and 1s in the player columns). I will record how many plays each lineup played so I can adjust the value in the ‘def_space’ column to a per-100 possessions rate which we can then take the z-score of. After all, those spacing values are pretty meaningless without some context. Here’s our next data frame:

There are now 201 rows in the data frame, one for each unique lineup. We have a dependent variable to represent the success in spacing out the defense for each lineup. We can now turn this into a matrix equation so that we can approximate the value of each player. Here’s what the matrix equation we’re solving would look like for just the first five rows of the data frame:

Each beta value in x represents the impact in spacing of the corresponding player, which is what we’re looking to solve for in the Ax = b equation above. To directly solve such a matrix equation, one may try to multiply both sides of the equation by the inverse of A. But in this case, A is not invertible because the number of rows is not equal to the number of columns. In the matrix equation for the entire data frame and not just the first five rows, A has 1482 rows and 14 columns.
So, I need to minimize error to find an approximate value of x. One way of doing this is through the least squares method, where both sides of Ax=b are multiplied by the transpose of A. The transpose of A multiplied by A is invertible, so it is then possible to multiply both sides by this inverse to solve for x.

One problem with the least squares approximation in certain situations is its high variance. In statistics and machine learning, every model has a certain amount of bias / variance and there is a trade-off between the two.
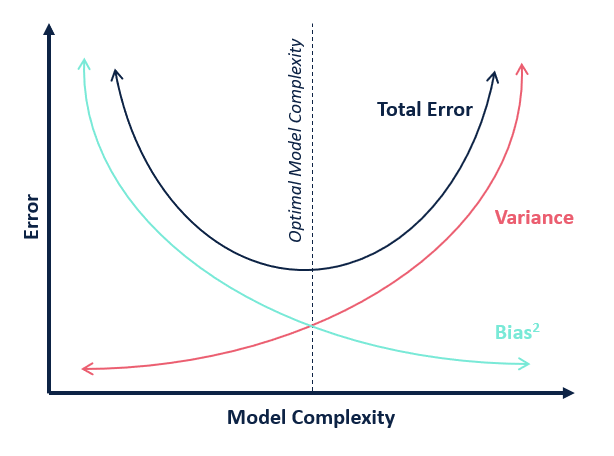
By adding a penalty component to the least squares model, the bias would increase slightly but the variance would be reduced drastically, therefore further minimizing the total error of the model. This is the idea behind ridge regression. The least squares method minimizes the loss function (the sum of squared errors), which is an unbiased approximation because everything is weighed equally. In ridge regression, the x values are penalized which moves the solution away from the least squares’ unbiased approximation. Because the penalties are not all equal, there is some additional bias in this approach. According to the bias-variance trade-off, the variance decreases along with this increase in bias.
Here’s the solution for x with ridge regression:

All that’s left to do is find an optimal lambda value. Let’s visualize what’s happening by plotting the x coefficient for all 14 players for every lambda value from 0 to 100.

You can see the variance in the least squares approximation on the far left when lambda is zero. As you can see, the addition of the ridge parameter reduces this variance. You can also see the fact that the penalty in ridge regression is biased. The lines at the top and the bottom curve upward and downward far steeper than the ones that are already close to a value of zero. This demonstrates the aforementioned bias-variance trade-off.
Originally, the proposed method of selecting lambda was to just look at this plot and pick a nice looking number in the middle, like 50. Unfortunately, everybody wants to make things more difficult, so people complained that this method lacked objectivity. Now, it’s standard to use cross-validation to find an ideal lambda value. Cross-validation is when you test the accuracy your model with data that wasn’t used to train the model.
In other words, we’ll take the x solution that we calculate for a certain lambda value and we’ll multiply this x by the A matrix which represents the lineups from the new data. This will spit out predictions for b, which we’ll compare with the actual values of b. We’ll be able to find the lambda value which minimizes the error between the predicted and the actual b values. This only works if you have untrained data to cross-validate. Fortunately, I lied when I said there were only 1482 offensive plays from the Golden State Warriors available to us. There’s 881 more waiting to be tested on.
After doing the cross-validation, I found the lambda value which minimized the mean squared error (MSE) on the unseen data. I could then plug this into the matrix equation for ridge regression and it spits out our final x coefficients. I created a data frame matching each coefficient with the corresponding player along with the number of appearances the player made on the court. Here are the final results:

The top two players are by far the two best shooters on the team, and the bottom three players are all big men who don’t shoot threes at all. Given the relatively tiny sample size of this experiment, I’m pleasantly surprised by these results. There are a few things which don’t really make sense, like Shaun Livingston being ahead of Brandon Rush and Harrison Barnes, but again, aberrations are inevitable with a sample this small.
I certainly think it passes the eye-test more so than the results we get from simply subtracting the average defensive spacing when a player is on the court from the average defensive spacing when they are not on the court:

With this basic method, the top six players are the six players who play the most minutes with other starters. Draymond Green and Andrew Bogut are given credit for the success of Stephen Curry and Klay Thompson. I think it’s fair to say that ridge regression yields superior results despite the small sample size.