

Introduction
Every year, NBA teams hope to find a franchise-altering player through the league’s annual draft. Of course, this is easier said than done. Accurately evaluating collegiate talent is no simple task. It’s impossible to know how a player’s game will translate to the professional level. Highly-touted players like Anthony Bennett and Kwame Brown sometimes crash and burn out of the league, while a second-round pick who was drafted during a commercial break can become an MVP-level talent.
The goal of this project was to use Python’s machine learning capabilities in order to create a model that could forecast the future success of NBA draft picks.
Data Collection
First, I collected data that could be used to train the model. I compiled physical measurables and collegiate statistics for 259 prospects between the 2008 and 2014 drafts. I used Bart Torvik’s college basketball website for the individual player data, and I used the NBA’s stats website to get measurables such as height, weight, and wingspan for every player.
I also wanted to include a player’s position because certain variables might prove to be more important for different roles. For instance, rebounding ability is probably more essential for a center than a point guard. Of course, I needed to convert a player’s position, a categorical variable, into a quantitative form. I used one-hot encoding for this by creating five variables (one for each position). For example, a point guard would be given a PG value of 1 and a value of 0 for the other four positions. In the end, the model would have twenty-eight (or inputs). Now, it just needed a label (or output).
I initially tried using an advanced stat like Box Plus/Minus as the model’s label, but the results were not accurate when the algorithm was applied to recent draft classes. A metric solely based on box score stats can only do so much. I decided to shake things up and instead use a categorical approach. I used accolades to split players into the following tiers: MVP winners, All-NBA First Team players, All-NBA Second or Third Team players, and All-Stars. Then, I used conditional statements based on basic player statistics to split the remaining players into the following tiers: good starters, good role players, role players, fringe bench players, and players who flamed out of the league. The main statistic I looked at for the non-All-Star tiers was minutes played. After all, as a team, you want to draft a player who you can actually play for you and contribute, right?
Now, the training dataset was complete with twenty-eight features and a label for 259 different players. I proceeded to compile a testing dataset with the same twenty-eight features for 131 players drafted between the 2015 and 2019 drafts. I would then be able to create a model that could forecast the label (tier) for these players.
Random Forest Regression
I used the Random Forest Regression model for this task. As the name suggests, a random forest is just a bunch of trees — decision trees, to be exact. A decision tree is like a series of binary questions until it leads to an eventual output. Here’s a simple example I randomly found on the Internet.
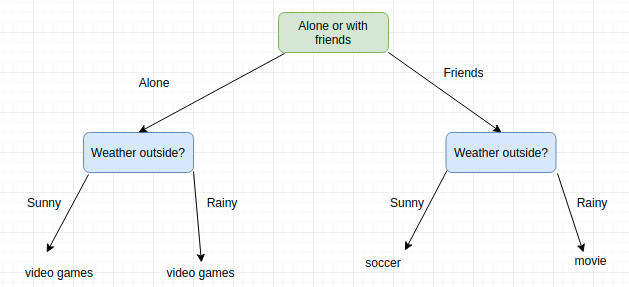
However, using a single decision tree for machine learning is typically not a good idea because it is more susceptible to overfitting. Overfitting is when your model represents the data too accurately. The model picks up so much of the noise in the training set that its performance in predicting the untrained data is negatively impacted. Imagine that a model’s accuracy on the trained dataset is 80% while its accuracy on the untrained dataset is just 30%. The model may have overfitted the trained dataset, sacrificing a lot of accuracy on the untrained dataset (which is what you’re really trying to maximize).
Therefore, a forest which composes of multiple decision trees can avoid overfitting by limiting the depth of the trees and then averaging the results together. The random forest model selects different sample points at random when building these different trees. In addition, it randomly chooses certain features to be considered at each “branch split” of the tree. Through this indiscrimination of data selection, bias is minimized. With thousands of decision trees in your random forest, you can then average the predictions of each tree.
So, I fit the Random Forest Regression model to the training set. The algorithm was then used to predict the labels for our test (or untrained) set with 129 different players.
Results
Before looking at the predictions for the prospects from the 2019 NBA Draft, I checked how well the model seemed to fare against the eye-test for the 2015, 2016, 2017, and 2018 draft classes.
The model predicted that the best player from the 2015 NBA Draft would be D’Angelo Russell, the second-overall pick. It also thought highly of Karl-Anthony Towns, Frank Kaminsky, Justise Winslow, Terry Rozier, and Kevon Looney. In the lottery, the model did not predict great things for Trey Lyles, who was projected to be nothing more than a role player. Most of these picks fared well, except for Kaminsky, who has not lived up to his expectations. In addition, the model failed to predict Devin Booker’s rise to stardom (as with all of the teams who let Booker fall to the 13th pick, of course).
The model forecasted a significant gap between Ben Simmons and the second-closest prospect from the 2016 NBA Draft. In the second tier, Buddy Hield, Jaylen Brown, Brandon Ingram, Kris Dunn, and Jamal Murray all received similar projections as high-end NBA starters. The model liked Skal Labissiere (28th overall) and Dejounte Murray (29th overall) as sleepers. Both players became bench contributors for their respective teams, although Labissiere hasn’t contributed much since being traded to the Trail Blazers. The model hit on many of these projections, but the Timberwolves’ selection of Dunn has definitely not panned out.
In the 2017 NBA Draft, the model seemed to agree with the league’s scouts. Markelle Fultz, Lonzo Ball, Jayson Tatum, Josh Jackson, De’Aaron Fox, and Dennis Smith Jr. (basically all of the top picks) were all given high grades. It did predict that Donovan Mitchell would be a solid starter, but obviously he has already surpassed even that expectation despite being a late lottery selection. Derrick White (29th overall) and Josh Hart (30th overall) were the forecasted sleepers, which has definitely panned out as both players have averaged over 22 minutes per game in their young careers.
The projected best player from the 2018 NBA Draft was Trae Young (note that Luka Doncic was not included because he has no collegiate stats). The model did not agree with the early selections of Marvin Bagley (2nd overall) and Mohamed Bamba (6th overall), predicting both players to just become decent starters, which isn’t what you’re looking for with those picks. It also had optimistic projections for Deandre Ayton and Mikal Bridges. It’s obviously far too early to judge these projections, though.
Finally, the 2019 NBA Draft.
| Player | Pick | Tier |
|---|---|---|
| Zion Williamson | 1 | 5.46 |
| Ja Morant | 2 | 4.69 |
| Jarrett Culver | 6 | 3.73 |
| Cam Reddish | 10 | 3.69 |
| Coby White | 7 | 3.41 |
| Nickeil Alexander-Walker | 17 | 3.06 |
| RJ Barrett | 3 | 3.03 |
| Brandon Clarke | 21 | 2.69 |
| Rui Hachimura | 9 | 2.55 |
| Grant Williams | 22 | 2.55 |
| Cameron Johnson | 11 | 2.50 |
| De'Andre Hunter | 4 | 2.43 |
| Tyler Herro | 13 | 2.43 |
| Romeo Langford | 14 | 2.16 |
| Jaxson Hayes | 8 | 2.16 |
| PJ Washington | 12 | 2.06 |
| Ty Jerome | 24 | 1.99 |
| Nicolas Claxton | 31 | 1.84 |
| Keldon Johnson | 29 | 1.59 |
| KZ Okpala | 32 | 1.39 |
| Mfiondu Kabengele | 27 | 1.29 |
| Nassir Little | 25 | 1.27 |
The model projects that Zion Williamson will become an All-NBA level player, while Ja Morant will be a high-end All-Star. Zion is the model’s highest-rated prospect of the entire five-year dataset, while Morant comes in at a respectable sixth (behind Zion Williamson, De’Aaron Fox, Trae Young, D’Angelo Russell, and Ben Simmons. Good company).
The model likes Nickeil Alexander-Walker, Brandon Clarke, and Grant Williams as later first-round picks who can perform above expectations. Clarke and Alexander-Walker both made the 2019 NBA Summer League First Team and Clarke even took home Summer League MVP honors, so these projections are looking plausible so far.
According to the model, the draft selections of RJ Barrett and De’Andre Hunter were not great value picks, though. It’s not an unpopular opinion that Barrett was picked too high, but only time will tell if he can live up to the hype with the New York Knicks.
Conclusion
The model’s past projections were certainly imperfect (although I’m still holding out hope on Frank Kaminsky becoming an All-Star…). At the end of the day, there are too many factors which can’t really be quantified. There was no human input in this model so I’m satisfied with the results, but human input is obviously a necessity in real life. Some physical measurements like hand size and vertical leap were excluded because many players did not participate in the NBA Combine. Perhaps the model could be improved if some of this data was available for all players. For now, these projections can just serve as some added excitement for Pelicans and Grizzlies fans.