

After a long, grueling journey, the Virginia Cavaliers emerged victorious in the 2019 NCAA men’s basketball tournament. It wasn’t a huge surprise — the Cavaliers had the second-best odds to be the ones cutting down the nets in Minneapolis. However, the events that led to this moment included plenty of shockers. For example, the Auburn Tigers reached the Final Four for the first time in team history after upsetting the North Carolina Tar Heels and the Kentucky Wildcats. Who could have predicted that? Well … we did.
Our statistical model excelled in its inaugural appearance. On ESPN’s Tournament Challenge, it finished in the 99th percentile of all brackets. That’s shockingly good for a purely statistical approach. A few weeks ago, we observed how the model stacked up against other objective techniques of bracketology after the first round. Now, we can take a look at the final results.
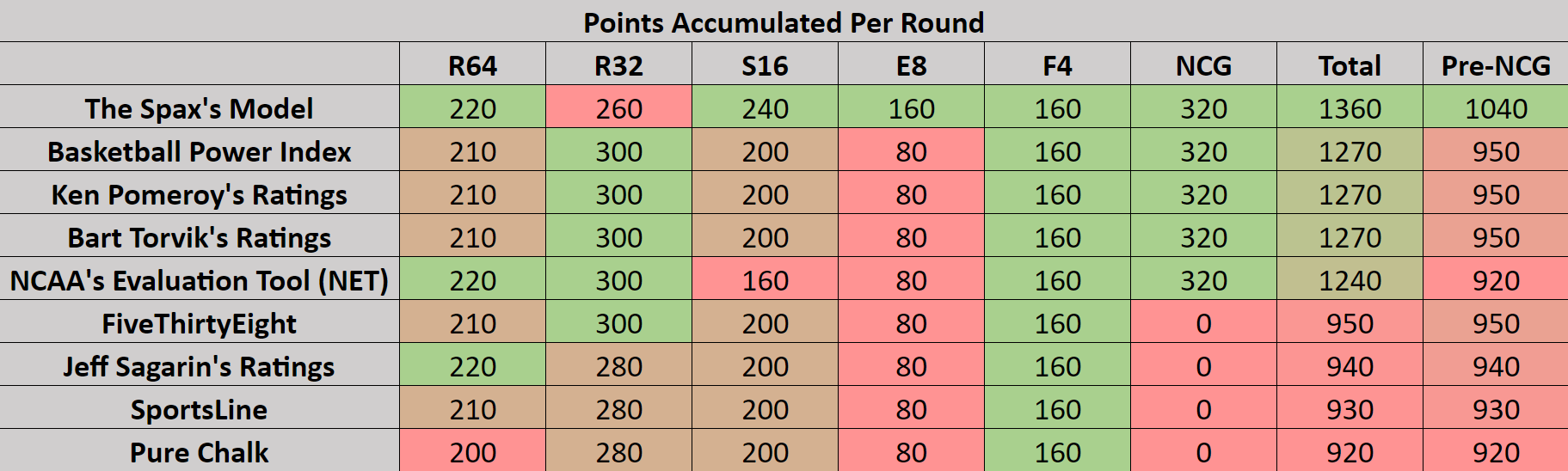
Other than a slip-up in the Round of 32, our model rose above the rest of the competition. Because of the enormous number of points rewarded to brackets which correctly predict the National Championship winner, I calculated the points accumulated before the national championship game as well as the real total. In the last column, you can see that other than our own model, every model performed at around the same level going into the final game. The final result just increased the gap.
While a final score of 1360 is undoubtedly amazing, there were obviously a few predictions which the model missed on. The most notable of which is likely the Texas Tech Red Raiders’ run to the National Championship. Our algorithm gave Michigan a 52.28% chance at beating the Red Raiders in the Sweet 16. In reality, Texas Tech came out on top by 19 points. Also, while our model gave the 12-seed Oregon Ducks a decent 42.03% chance at pulling off a first-round upset over the Wisconsin Badgers, it didn’t anticipate the Ducks advancing all the way to the Sweet Sixteen.
There are a few improvements which could be made to this model. It is currently made up of 30 weighted inputs, but that number could easily be increased. Also, the algorithm is essentially an example of machine learning — theoretically, it should improve every year as the dataset grows. In other words, the model should learn from its mistakes and adjust its formula to account for them. Of course, the problem with this idea is the amount of randomness and luck inherently ingrained into the tournament. Auburn could have easily lost to New Mexico State (seriously, though), in which case our entire model would have looked very stupid.
I also believe that this model could be used even more effectively if combined with actual human knowledge of college basketball. If Duke had won the tournament, one of my brackets (which were based on this model) would have finished with 1500 points. Considering I have nearly no actual knowledge of college basketball, that’s quite impressive. Maybe a college basketball fanatic could have pushed the limit even further.
It’ll be interesting to see how well the model performs in future years. Maintaining any consistency in a tournament called March Madness would be very impressive but not quite realistic. All we can say with certainty is that this algorithm was the most accurate of its kind in this year’s tournament. That’s pretty cool.