

In Part I, I collected 1326 observations1 of 189 features for the purpose of figuring out what exactly sets players apart so that a new system could be created for categorization. After all, the traditional five position system is getting a little stale.
I used principal component analysis (PCA) to reduce the 189 features into 81 new dimensions that are made up of the previous features. The 81 new dimensions explain 99% of the total variation in the data, which will hopefully allow us to create a reasonable system of classifying NBA players.
Now we have two major decisions to make. We need to choose a clustering algorithm to categorize the 195 players, and we need to determine how many clusters should be made.
The first answer to question one that comes to mind is k-means clustering, which is perhaps the simplest and most popular clustering algorithm out there. It has its deficiencies (it struggles with non-circular shapes, for instance), but it is very easy to implement. Let’s try it out.

There is no widely-accepted best method for finding the optimal number of clusters (k). Therefore, it’s probably best to try out multiple techniques to make sure the results line up.
Two common ways for finding the best number of clusters in k-means clustering are the elbow method and the silhouette method. I applied both methods to our data to generate the following plots:

Using the elbow method, the optimal number of clusters is when the within cluster sum of squares (WCSS) clearly begins to level off (so it forms an elbow). The problem is … it doesn’t really level off here. The silhouette score, meanwhile, is best when it’s closest to a value of one. In this case, the maximum silhouette score is achieved when k=2. Unfortunately, I don’t think placing every NBA player into one of two categories is the answer to our problem here.
Therefore, I’ll instead roll with a model-based algorithm called Gaussian mixture model clustering. It is an unsupervised learning method which assumes that there are a certain number of Gaussian distributions, each representing a cluster. We just have to figure out the optimal number of clusters, which can be done using the Bayesian information criterion.

The absolute minimum is achieved at k = 8, which makes it the best number of clusters for our data.
Now, the actual clustering is extremely easy:
gmm = GaussianMixture(n_components=8).fit(principalComponents) labels = gmm.predict(principalComponents) testdf['cluster'] = labels
Just like that, we’ve placed 1326 single-season performances from the past seven seasons into one of eight categories.
We can visualize the clusters using our initial PCA (which reduced the data into two dimensions) from Part I.

The graph clearly illustrates the fact that the clustering takes into account the two principal components which explain 47.2% of the total variation, but they’re also influenced by the other 79 clusters that explain the remaining 51.8% of the total 99% variation that’s explained by our 81 principal components. Notice the red and purple dots and how they’re basically scattered within each other in a fashion that seems pretty random. That’s because whatever sets those two clusters apart clearly isn’t a part of the two principal components used as the axes for the graph.
We can also observe that each cluster probably doesn’t have the same amount of players, which is easy enough to confirm:
testdf.cluster.value_counts()
4 237 7 227 6 202 1 185 3 170 2 107 0 100 5 98 Name: cluster, dtype: int64
The numbers on the left represent the eight different clusters, while the numbers on the right indicate how many of the 1326 single-season player performances fall into each cluster.
Representing the clusters with a number isn’t very useful to us, though. So, I went through each cluster to try and figure out what exactly sets these players apart. Here are the eight types of players in the NBA:
1. High-Usage Big Men
Description
These players probably aren’t bringing the ball up the court all the time like a point guard, but they are still often the focal points of their offenses. The superstar centers in the league typically fall into this category.
Key Stats
These players lead all clusters in rebounds, every hustle stat,2, points scored and efficiency in the paint, points scored and efficiency as the roll-man in pick-and-roll situations, and defensive box plus/minus.
These players are last among all clusters in 3-pointers made from the top of the key and percentage of 3-pointers that are unassisted.
Notable Players
’19 Nikola Jokic, ’18 Anthony Davis, ’18 Karl-Anthony Towns
2. Versatile Forwards
Description
Players in this cluster tend to be versatile offensively while also being strong rebounders for the forward position. They are not quite superstar players, however– they offer all-around aptitude but usually aren’t particularly outstanding scorers or playmakers despite dribbling the ball relatively often.
Key Stats
These players boast the second-highest contested shots, loose balls recovered, and box outs. Their average defensive rating is also the second-best among all clusters. Additionally, this cluster averages the second-most distance traveled offensive and defensively. Among clusters that aren’t mostly filled with guards, players within this cluster average the most dribbles per touch.
They’re not known for their ability to shoot the ball immediately after pass, as this cluster’s catch-and-shoot field goal percentage is the second-lowest among all eight clusters.
Notable Players
’15 Jimmy Butler, ’15 Kawhi Leonard, ’16 Giannis Antetokounmpo
3. Stretch Forwards / Big Men
Description
Stretch forwards and big men include players who may not dribble the ball as often as versatile forwards, but they’re still able to score due to their versatile shooting ability. As a result, they’re able to stretch the floor more than other players of their height, though many of them are still more than capable at scoring in the paint.
Key Stats
On average, players of this cluster score 25.3% of their points from mid-range jumpers, by far the most of any cluster. Additionally, their 41.5% catch-and-shoot FG% is the most for any cluster, likely due to their skill along with the fact that many of these shots come from inside the arc.
Stretch forwards / big men travel the least distance both offensively and defensively. On average, 6.4% of their points come from fast break opportunities, the lowest rate of any cluster.
Notable Players
’14 Kevin Love, ’15 Anthony Davis, ’14 Dirk Nowitzki
4. Ball-Dominant Scorers
Description
These guards and forwards create shots for themselves far more often than other players. They are known for their ability to score off of the dribble. This cluster feature the league’s best scorers and many of the best playmakers who are better scorers than players in the floor general cluster.
Key Stats
Most notably, ball-dominant scorers score 23.96 points per 36 minutes on average. No other cluster hits the 20 mark. Additionally, 13.4% of their points come from isolation plays, the highest rate for any cluster. They drive to the basket more than any other cluster, and they score unassisted at a higher clip than any other cluster.
Interestingly, players within this cluster also average the second-lowest effective field goal percentage and true shooting percentage. Perhaps this is due to the fact that they attempt more shots off of the dribble that tend to be more difficult. While certain players (like the notable players listed below) can get away with this, other players like ’15 Kobe Bryant become far less than efficient.
Notable Players
’14 Kevin Durant, ’16 Stephen Curry, ’19 James Harden
5. Floor Generals
Description
Almost all of the players in this cluster are guards. Their game is typically centered around their playmaking, not their scoring.
Key Stats
As you would expect, floor generals average more passes than any other cluster. While they don’t get as many assists as ball-dominant scorers, they are more efficient passers, boasting a far better average assist-turnover ratio. Because of their important duties in leading the offense, they touch the ball more than any other cluster. Additionally, they possess the ball longer within each touch the most, and they dribble the most per touch.
They are typically pass-first players — they pass out of drives more than any other player. However, when they do score, it’s usually off of drives and plays in which they’re the pick-and-roll ball-handler. The percentage of their points that come from these situations is larger than any other cluster.
Notable Players
’14 Goran Dragic, ’14 Mike Conley, ’15 Kyle Lowry
6. Traditional Centers
Description
Traditional centers tend to be strong rebounders and rim-protectors, but they rarely do much more than that. If they ever shoot the ball, it’s probably going to come from shots around the rim.
Key Stats
This cluster leads all clusters in stats related to offensive rebounds. They block more shots than any other cluster. The percentage of their points that come from the paint is the highest of any cluster, as with the percentage of their 2-pointers that are assisted. They spend also spend the greatest percentage of their time on the floor without the ball in their possession. On average, traditional centers also stand taller than players from other clusters.
In addition, this cluster finishes last in a whopping 74 of the data’s 189 features. That’s a lot. I can’t name them all, but here are some: assists, steals, three-point makes and attempts, deflections, charges drawn, loose balls recovered, drives, free throw percentage, time of possession, and average dribbles per touch.
Notable Players
’14 Joakim Noah, ’17 Rudy Gobert, ’15 DeAndre Jordan
7. Sharpshooters
Description
These players rarely initiate plays. Instead, they’re known for their ability to launch deep jumpers directly off of passes. This cluster is primarily made up of guards, but also includes some forwards.
Key Stats
Players in this cluster average the most points off of catch-and-shoot situations. They lead all clusters in efficiency from both corners. Sharpshooters also take (and make) more threes than any other cluster.
On average, sharpshooters are last among all clusters in all rebounding stats. They record less screen assists and pass less often than any other cluster. Players in this cluster are also last in blocks and score in the paint less than any other cluster.
Notable Players
’15 Klay Thompson, ’14 Wesley Matthews, ’19 Buddy Hield
8. Low-Usage Role Players
Description
These players usually don’t have the ball in their hands. If they do, they’re rarely expected to do much with it, unless they’re spotting up for a 3-pointer. Even then, their jump shooting ability isn’t as strong as players in the sharpshooter cluster. However, these players do tend to be better defenders than sharpshooters.
Key Stats
On average, these players score 48.3% of their points from 3-pointers, 15.7% in fast breaks, and 17.4% off of turnovers. All of these rates are the highest for any cluster. Players within this cluster also attempt more 3-pointers from either corner than other clusters, and they travel the greatest distance defensively and overall. On the defensive side of things, this cluster boasts the second-highest defensive box plus/minus among all clusters despite not leading the pack in either steals or blocks.
These players score the least points, shoot the ball the least, have the lowest usage percentage, draw the least amount of fouls, etc.
Notable Players
’17 Draymond Green, ’14 Nicolas Batum, ’15 Danny Green
Great, we’ve established our eight clusters: high-usage big men, versatile forwards, stretch forwards / big men, ball-dominant scorers, floor generals, traditional centers, sharpshooters, and low-usage role players. Let’s visualize the distribution of “old positions” within each cluster using a stacked horizontal bar chart.
pdf = testdf.groupby(['cluster']).sum()[['C','F','G']]
ind = np.arange(len(np.unique(labels)))
width = 0.4
p1 = plt.barh(ind,pdf['G'], width, color='r',label='G',edgecolor='black')
p2 = plt.barh(ind,pdf['F'], width, color='g',left=pdf['G'],label='F',edgecolor='black')
p3 = plt.barh(ind,pdf['C'], width, color='b',left=np.array(pdf['G'])+np.array(pdf['F']),label='C',edgecolor='black')
plt.xlim(0,250)
plt.xlabel('players')
plt.title('distribution of positions in clusters')
plt.gca().invert_yaxis()
plt.gca().set_yticks(np.arange(8))
plt.gca().set_yticklabels(['high-usage big men','versatile forwards','stretch forwards / big men','ball-dominant scorers','floor generals','traditional centers','sharpshooters','low-usage role players'])
plt.legend(loc='best')
plt.show()
The three “big men” clusters (high-usage big men, stretch forwards / big men, and traditional centers) are the three smallest clusters. That’s unsurprising, considering the number of centers in the league is smaller than the number of guards and forwards. Also, the stretch forwards / big men cluster is named as such due to the relatively even distribution of, well, forwards and big men.
Only three centers fell into the low-usage role player cluster: ’14 Channing Frye, ’19 Brook Lopez, and ’20 Marc Gasol. Meanwhile, 94.9% of floor generals are guards. Three of the twelve odd ones out are single-season performances from Evan Turner from 2014 to 2017.
Before I wrap things up in this article, let’s use this data to create an 8-man All-NBA team by finding the best players this season from each cluster. I’ll use VORP (Value Over Replacement Player) to determine which player is the best. It’s definitely a flawed metric, as is any all-in-one metric, but this is just a quick exercise for fun.
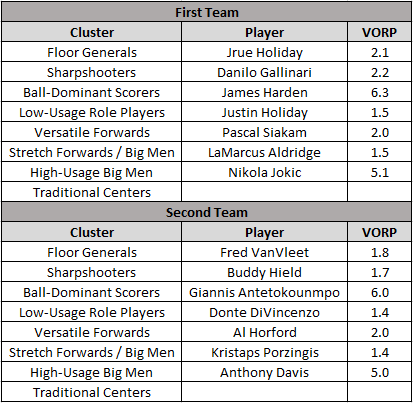
Of the top 20 players leading the league in VORP this season, 13 are ball-dominant scorers and the other 7 are high-usage big men. So, needless to say, these certainly aren’t all the best players in the NBA. Justin Holiday isn’t better than LeBron James.
Anyway, basically all of these cluster designations seem to make sense. Everything’s normal here — all good!
Well, except for the fact that none of the 196 eligible players from the 2019-20 regular season qualified as a traditional center. Or last season. Or the year before. Yeah, it’s a bit odd. I think it’s the consequence of clustering with a seven season sample size — big men from 2014 are quite different from 2020. I guess the real traditional centers don’t get enough minutes to qualify, and the others have just evolved into high-usage big men. It’s weird and maybe indicative of a flaw in this process.
Anyway, I think that’s a good stopping point for this article. I plan on using the data from this short series for new tasks in the near future. Once again, you can see Part I here, and much of the code from this part here.