

In a recent two-part series, I used dimensionality reduction and Gaussian mixture model clustering to create a new system of classifying NBA players based on comprehensive data from the past seven years. In summary, every single-season performance from an eligible player since 2014 can be placed into one of the following eight groups: high-usage big men, versatile forwards, stretch forwards / big men, ball-dominant scorers, floor generals, traditional centers, sharpshooters, and low-usage role players. The distribution of conventional positions within each cluster is shown below.

While there’s certainly a relationship between conventional positions and my eight player clusters, there’s also clearly some more interesting nuances. We typically label guards as either point guards or shooting guards, but those labels fail to truly describe how they act on the court. A guard can be a floor general, a ball-dominant scorer, a sharpshooter, or a low-usage role player. On some rare occasions, they even fall into the category of versatile forwards.
Needless to say, I think the additional insights offered by this classification system gives us some more opportunities for analyzing the NBA. In this article, I want to use these eight different classifications to gauge the effectiveness of various types of lineups in the NBA.
All of the data and code in this article can be found at this link. I won’t get into anything in the data_preparation file, but it’s all rather simple — it just covers the process of creating the data frame tf which contains all of the information needed for our analysis. Part of the data preparation includes getting the full player classifications for eligible players from each of the past seven seasons. Those can be found in this CSV file.
Anyway, after going through everything in the data_preparation file, we are left with the data frame tf. Here’s a snippet:

The value in the team column represents the identifying number for which the team which the corresponding lineup was playing for during the year listed in ssn. The poss column lists the total number of possessions played by that lineup in the corresponding season. The ortg, drtg, and nrtg columns indicate the offensive, defensive, and net ratings for that lineup. The column tm_nrtg indicates the relevant team’s total net rating on the season, while the value in avg_poss represents the mean number of possessions for lineups belonging to that specific team.
The data frame contains 1564 rows. It does not include any lineups containing players who were not eligible1 for the classification process done in previous articles
Now, let’s add eight columns that’ll serve as individual indicators for the eight different player classifications. The value in each column will represent how many players belonging to that classification are in the lineup represented by each row.
clusters = list(set((tuple(tf.p1.unique()) + tuple(tf.p2.unique()) + tuple(tf.p3.unique()) + tuple(tf.p4.unique()) + tuple(tf.p5.unique()))))
clusters.sort()
for i in range(1,len(clusters)+1):
tf['c'+str(i)] = 0
def stint(p1,p2,p3,p4,p5):
local_clusters = [p1,p2,p3,p4,p5]
return local_clusters.count(clusters[i-1])
for i in range(1,len(clusters)+1):
tf['c'+str(i)] = np.vectorize(stint)(tf.p1,tf.p2,tf.p3,tf.p4,tf.p5)
tf = tf[['ssn','poss','tm_nrtg','avg_poss','ortg','drtg','nrtg','c1','c2','c3','c4','c5','c6','c7','c8']]
tf.head()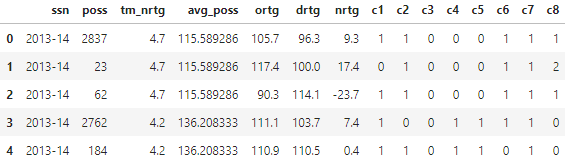
The first lineup had one player belonging to each of cluster one, two, six, seven, and eight. They managed to achieve a net rating of 9.3 over 2837 possessions. The second lineup had two players from the eighth cluster and outscored their opponents by 17.4 points per 100 possessions. That’s amazing, but seems oddly high. On the other side of things, the third lineup was outscored by 23.7 points per 100 possessions. That’s definitely way too extreme.
The problem, as I’m sure you’ve noticed, is the small sample size. The first lineup played 2837 possessions together — plenty enough to draw conclusions based on their metrics in that time. The second cluster only played 23 possessions together, though. That’s approximately one quarter of a game. One explosion from Klay Thompson away from a skewed sample. We definitely can’t feed numbers like -23.7 into our model without adjustment.
The answer lies in something called Bayesian inference. The idea behind Bayesian inference is to update a model when more information becomes available. In this case, we need to find more information to update the net rating metric because of our aforementioned problem with low sample sizes. That’s where tm_nrtg and avg_poss comes in.

The following graphic is taken from this outside article, which describes a way to calculate Bayesian net rating. If you look at the equation, you’ll notice that the the Bayesian net rating approaches the team’s overall net rating as the number of possessions for lineup i approaches zero. In other words, it starts with the prior belief that the lineup is average. As more possessions are fed into the model, it builds off of that presumption.
Using this equation, the net rating of -23.7 for the third lineup would become a less extreme value of -5.21. Sounds good to me! Let’s put it to use and update the nrtg column.
def adj_nrtg(tm_nrtg,nrtg,poss,avg_poss):
return ((avg_poss*tm_nrtg)+(poss*nrtg))/(avg_poss+poss)
tf.nrtg = np.vectorize(adj_nrtg)(tf.tm_nrtg,tf.nrtg,tf.poss,tf.avg_poss)Our analysis of lineups is now less likely to be skewed by extreme values brought upon by small sample sizes. We can now go ahead and throw out the columns we no longer need in order to clean up tf.
tf = tf[['c1','c2','c3','c4','c5','c6','c7','c8','nrtg']] tf.head()

We’ve set ourselves up nicely to run a quick ridge regression to find the coefficients for each of our eight clusters. I dove into the specifics of ridge regression in this previous article, so feel free to check it out if you’re interesting. The important thing to know here is that it includes a parameter known as alpha which we’ll need to optimize by maximizing the coefficient of determination (R²) in a quick cross-validation.
from sklearn.linear_model import Ridge
import matplotlib.pyplot as plt
features = ['c1','c2','c3','c4','c5','c6','c7','c8']
msk = np.random.rand(len(tf)) < 0.8
train = tf[msk].reset_index(drop=True)
test = tf[~msk].reset_index(drop=True)
row_list = []
for n in range(0,1001):
clf = Ridge(alpha=n)
clf.fit(train[features],train.nrtg)
score = clf.score(test[features],test.nrtg)
dict1 = {'alpha':n,'score':score}
row_list.append(dict1)
alpha_df = pd.DataFrame(row_list)
plt.plot(alpha_df.alpha,alpha_df.score)
plt.xlabel('alpha')
plt.ylabel('coefficient of determination (R^2)')
plt.title('ridge regression parameter tuning')
plt.xlim(0,1000)
plt.tight_layout()
plt.show()
As alpha initially increases, the coefficient of determination (R²) gradually increases before peaking at around 100. After that point, R² drops off as alpha increases.
Let’s find the absolute peak of the curve:
alpha = alpha_df[alpha_df.score == alpha_df.score.max()].alpha.values[0] print(alpha)
105
So, our alpha parameter is set at 105. Great. We can now proceed with the ridge regression.
clf = Ridge(alpha=alpha) clf.fit(tf[features],tf.nrtg) coefficients = clf.coef_
The array coefficients contains eight values — one for each cluster classifying NBA players. Here’s a quick plot illustrating these coefficient assignments.
plt.scatter(coefficients,clusters,edgecolor='black')
plt.axvline(x=0,c='black',linewidth=1)
plt.rc('grid', linestyle='dashed',color='black',alpha=0.4)
plt.grid()
plt.title('net rating coefficients for player clusters')
plt.xlabel('coefficient')
plt.xlim(-1.5,2)
plt.tight_layout()
plt.show()
According to our ridge regression model, ball-dominant scorers have the greatest positive impact on a lineup’s net rating. No surprise there — all the best guards and forwards in the NBA are classified as ball-dominant scorers. Next up are low-usage role players, which is a bit more of a surprise. Justin Holiday has the highest VORP among low-usage role players in the league this season. It’s not exactly a star-studded group of players. The only other player cluster with a positive coefficient is the sharpshooters. Their value makes sense, as spacing in the NBA is more important than ever before.
On the other side of zero, big men aren’t getting any love. This model seems to support the small ball revolution. The least valuable players apparently belong to the traditional centers cluster. In Part II of my classification series, I pointed out that no player over the past three seasons was classified as a traditional center. It seems like a dead cluster. Maybe we just found out some evidence for why that is.
Traditional centers can’t be completely useless though, right? They specialize in rebounding and rim protection, so they must be pretty valuable defensively. Let’s check. We can repeat the previous process and cook up ridge regression models for predicting offensive and defensive rating so we can analyze both sides of the ball separately. I’m not gonna bother including the code in the name of avoiding redundancy.

The plot of coefficients from the offensive rating model doesn’t make a great case for traditional centers. They’re by far the least valuable offensive players. The only other negative offensive clusters are two other classifications for big men.
Granted, those players do make up for some of that offensive ineptitude with their defense. After all, traditional centers and stretch forwards / big men were both assigned negative coefficients by the defensive rating model. A lower defensive rating means that the lineup held their opponents to less points, so that’s actually good. But I put the same x-axis scale on both graphs to demonstrate that the variance in offensive impact among clusters appear to be greater than the variance in defensive impact. As the graph of net rating coefficients showed, the coefficients for big men were still negative because their lack of offensive value outweighed any of their defensive value.
In other news, low-usage role players are the only cluster with a positive (as in good, not a positive coefficient) impact on both offensive and defensive rating. Again, I don’t really have an explanation for why that is. Their strong defensive rating coefficient isn’t a result of the centers in their cluster — only three centers2 have ever been categorized as low-usage role players. Maybe the fact that they have such a low offensive usage allows them to expend more energy on defense? But then why is their offensive rating coefficient so high? No idea. Any theories?
I’ll wrap this article up here. In Part II, I’ll use an XGBoost model to find the most and least optimal player classification combinations within five-man lineups, among other things. All of the code used to make this article (except for the final two subplots) can be found here.